Large language models have grown increasingly complex, with some containing hundreds of billions of parameters. Running these models at inference time is typically computationally intensive. One approach to address this challenge is Mixture of Experts (MoE) , a machine learning technique that divides a model into separate subnetworks, or “experts.” Each expert focuses on a subset of the input data, and only the relevant experts are activated for a given task, rather than using the entire network. This approach enhances efficiency by allowing models to scale without a proportional increase in compute costs.
Mixture of Experts is not a new concept; it was first proposed in 1991. However, it is experiencing a resurgence and is being used in leading large language models today, such as Mixtral 8x7B and DeepSeek R1.
Architecture and Functionality
In a typical MoE model, there is an input and an output, with many expert networks in between. These expert networks, such as Expert Network 1, Expert Network 2, …, Expert Network N, are situated between the input and the output. Additionally, there is a gating network (Router) that sits between the input and the experts. This Router acts as a traffic cop, deciding which experts should handle each subtask.
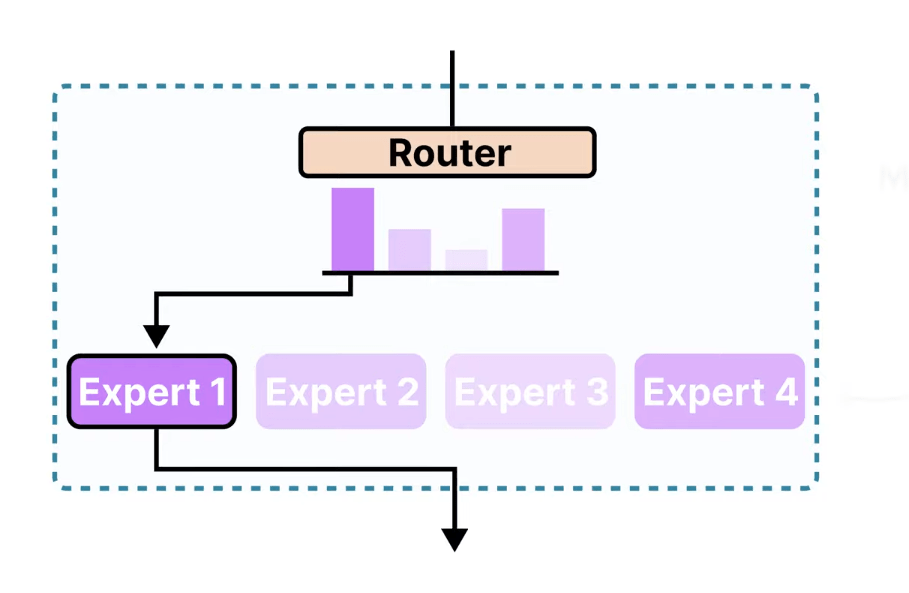
When a request comes in, the Router selects which experts to invoke for that input. It assigns weights to these experts, and these weights are used to combine the results from the selected experts to produce the final output. Essentially, the results from the chosen experts are combined to form the final output.
An MoE layer can be Dense or Sparse: Dense MoE distributes tokens across all experts.

Whereas Sparse Mixture of Experts (MoE) selects a few experts and aggregates their weighted outputs, its computational efficiency stems from activating only a subset of experts at a time. For instance, Mixtral 8x7B consists of eight experts, each with 5.6 billion parameters. Although the model has a total of 47 billion parameters when fully loaded, it activates approximately 13 billion parameters during inference. This selective activation makes it significantly faster than its total parameter count would suggest.

Chinese startup DeepSeek’s engineers stated that they required only 2,000 GPUs to train the DeepSeek V3 model, which utilizes a Mixture of Experts (MoE) architecture. In contrast, Meta reportedly used over 100,000 Nvidia GPUs to train its latest open-source model, Llama 4. DeepSeek R1 integrates chain-of-thought reasoning with reinforcement learning and also employs MoE architecture.
Mixture of Experts offers a promising solution to the computational challenges associated with large language models. By selectively activating only the necessary components, MoE allows for more efficient scaling and reduced computational costs, making advanced AI capabilities more accessible and scalable.

Leave a comment