In recent years, generative AI has taken the world by storm. However, as powerful as these AI systems are, their capabilities can be significantly enhanced by incorporating external data. This is where vector embeddings and Retrieval-Augmented Generation (RAG) come into play.
What Are Vector Embeddings?
At their core, vector embeddings are numerical representations of objects such as text, images, videos, or even audio. Machine learning algorithms work with numbers. Vector embeddings are the bridge that translates these objects (text, images etc) into a format that computers can understand. Think of them as coordinates in a multi-dimensional space, where each point represents an object.
For example, consider the sentences:
- “A sad boy is walking.”
- “A little boy is walking.”
- “A little boy is running.”
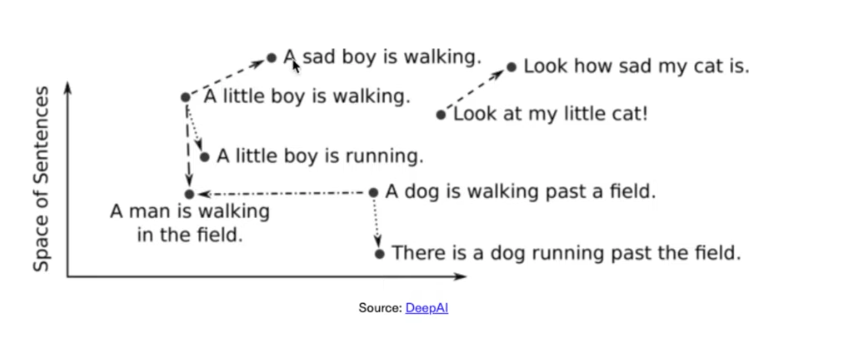
These sentences can be converted into vector embeddings, and the distance between these vectors represents their similarity. The closer the vectors are in this multi-dimensional space, the more similar the objects they represent.
To better understand vector embeddings, let’s visualize them in a 3D space. Imagine each object (e.g., a word, image, or audio clip) is represented as a point in this space. The coordinates of these points are determined by their embeddings.
For instance, consider colours represented in RGB (Red, Green, Blue) coordinates:

- Blue might be mapped to coordinates (2, 71, 254)
In this space, colors like Payne’s Gray and Cadet Blue, which are visually similar, will have embeddings that are close to each other. This clustering of similar objects is a key feature of vector embeddings and enables applications like recommendation systems and search engines.
How Are Vector Embeddings Created?
Creating vector embeddings has evolved significantly over the years. In the past, feature engineering was the primary method, where domain experts manually quantified features like shape, colour, or texture to capture an object’s semantics. Imagine you’re teaching a friend how to recognise different types of fruit. You have a basket full of apples, bananas, and oranges. To help your friend learn, you point out specific features of each fruit:
- Apples are round and red or green.
- Bananas are long and yellow.
- Oranges are round and orange.
By focusing on these features—like color, shape, and size—your friend can easily tell the fruits apart. However, this approach is time-consuming and not scalable.
Today, advancements in machine learning have led to models specifically designed to generate vector embeddings. These models are trained to translate objects into embeddings automatically. Some popular examples include:
- Text Data: Models like Word2Vec, GloVe, and BERT transform words, sentences, or paragraphs into vector embeddings.
- Images: Convolutional Neural Networks (CNNs) such as VGG and Inception convert images into embeddings.
- Audio: Similar models can be applied to audio data, enabling applications like voice recognition and music recommendation.
Storing and Querying Vector Embeddings
Once vector embeddings are created, they need to be stored in a way that allows for efficient retrieval. This is where vector databases and vector indexes come in. These systems are designed to handle the unique structure of vector embeddings, enabling fast and scalable searches.
Popular vector databases like Pinecone and Weaviate are optimised for this purpose. They allow users to:
- Store embeddings along with metadata.
- Query the database to find embeddings that are similar to a given input.
For example, in a corporate knowledge base, a user might ask, “How do I open a support ticket?” The system would:
- Convert the query into a vector embedding.
- Search the vector database for embeddings that are closely related to the query.
- Return the most relevant results, such as articles or FAQs about support tickets.
What Is Retrieval-Augmented Generation (RAG)?
While vector embeddings are powerful on their own, they become even more impactful when combined with Retrieval-Augmented Generation (RAG). RAG is a framework that enhances generative AI models by allowing them to retrieve relevant information from external sources before generating a response.
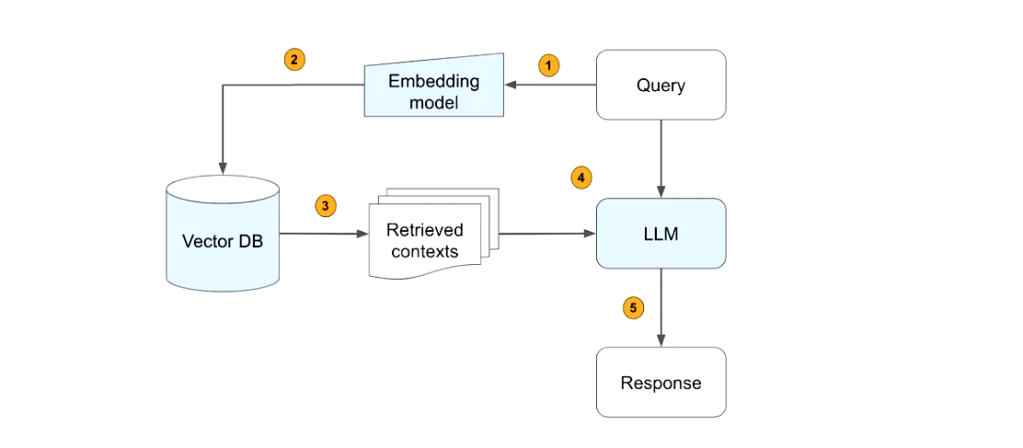
Here’s how RAG works:
- Retrieval: When a user inputs a query, the system retrieves relevant documents or data using vector embeddings.
- Augmentation: The retrieved information is fed into a generative AI model(LLM).
- Generation: The model generates a response based on both the query and the retrieved data.
This approach is particularly useful for applications like question-answering systems, where the AI needs to provide accurate and contextually relevant answers.
Use Cases for Vector Embeddings and RAG
The combination of vector embeddings and RAG opens up a wide range of applications:
- Recommendation Systems: Suggesting products, movies, or podcasts based on user preferences.
- Search Engines: Enabling text, image, or audio search by finding similar embeddings.
- Chatbots and Q&A Systems: Providing accurate answers by retrieving relevant information from a knowledge base.
- Fraud Detection: Identifying outliers in financial transactions by analyzing embeddings.
- Content Creation: Assisting writers, designers, and creators by retrieving relevant references or inspiration.
Conclusion
Vector embeddings and RAG are transforming the way we interact with AI systems. As the field continues to evolve, we can expect even more innovative applications and advancements. So, the next time you interact with a recommendation engine or a chatbot, remember the role of vector embeddings and RAG in making it all possible!

Leave a comment